
PwC's 2026 Global CEO Survey found that 56% of CEOs said they got nothing from their AI adoption efforts. Not a modest return. Nothing. For a technology drawing billions of dollars of investment globally, that number points to something going wrong early in the process, usually before a single line of code is written.
One of the most common early mistakes is treating RAG and fine-tuning as interchangeable. However, they are not. In reality, these solve different problems, carry different costs, and suit very different types of situations.
In case you are a CTO, product lead, or decision-maker exploring custom LLM development services in the USA, this guide can help you. It explains both approaches in simple language so that you can figure out which one actually fits your situation.
Think of it as the decision framework you should have before your team writes a single line of code.
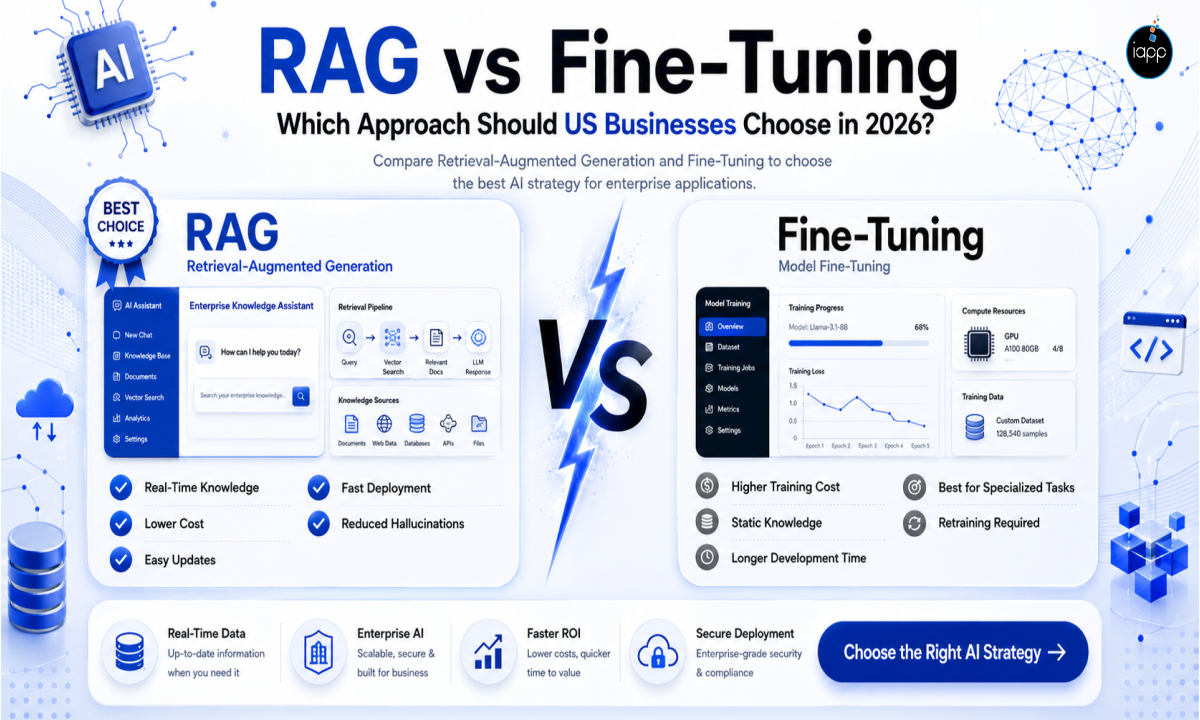
RAG means Retrieval-Augmented Generation. The name sounds complicated, but the concept is pretty simple.
Think of a standard large language model as a very well-educated employee who finished their education. They know a lot, but they have no idea about your company's internal policies, your latest pricing, or anything that changed in the past year.
RAG solves this by giving that employee a live search tool. When someone asks a question, the system first searches through your documents, databases, or internal knowledge base. Then it pulls out the most relevant pieces of information and hands all of it to the language model along with the original question. Thereafter, the model writes an answer using that fresh context.
The important thing to understand here is that the model itself is never changed. Its internal settings, called weights, stay exactly as they were. RAG only changes what information the model sees at the moment it generates a reply.
This makes RAG extremely practical for US businesses that need their AI to reflect current, company-specific information without the cost and time involved in retraining a model. It is the backbone of most RAG Development Services USA providers today, and for good reason.
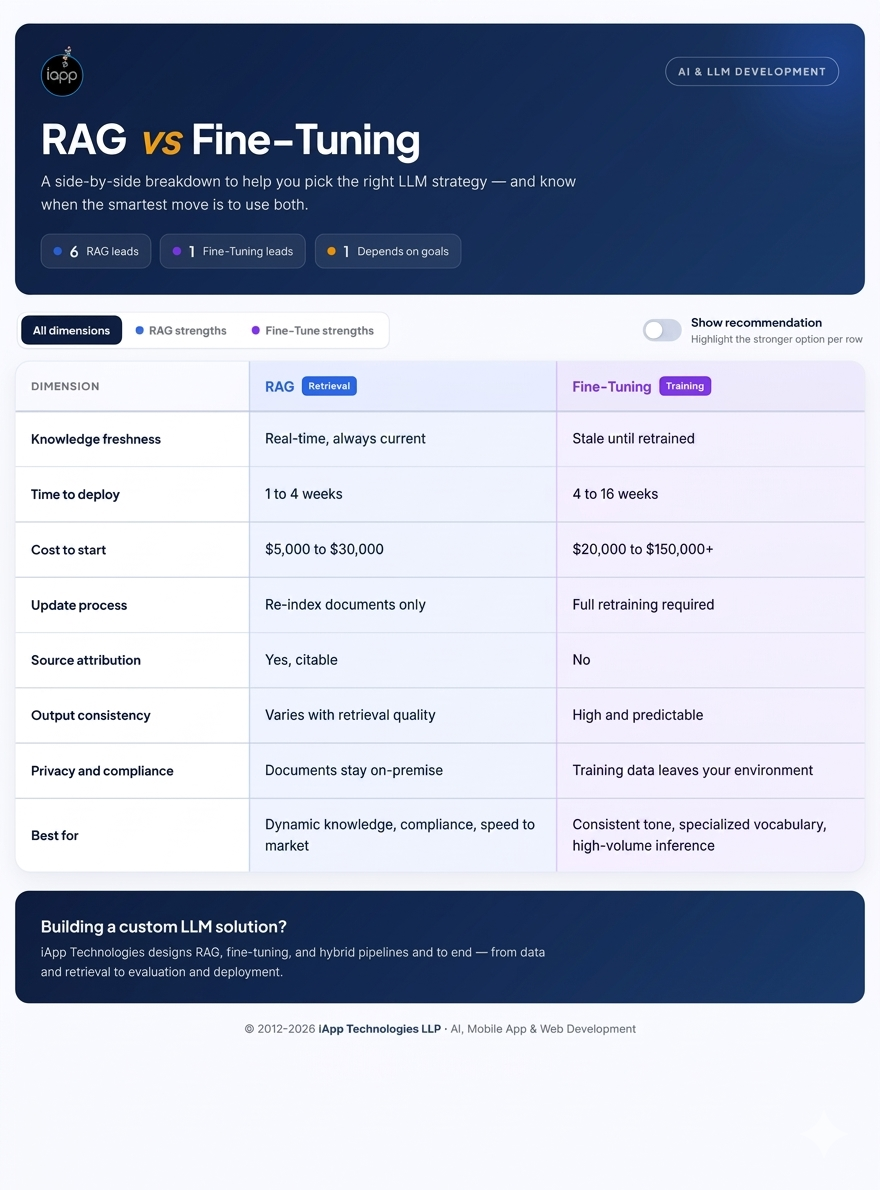
Your data changes regularly, such as product catalogs, legal documents, or pricing sheets.
You need the AI to cite sources so users can verify answers.
You want something in production within weeks, not months.
You are working under compliance requirements like HIPAA or SOC 2, where keeping documents on-premises matters.
The documents stored in your database are poorly organized or outdated, leading to bad retrievals and worse answers.
You need the model to consistently respond in a very specific tone, format, or brand voice.
Your application requires extremely fast responses where retrieval latency is a dealbreaker.
Tuning, on the other hand, is rather different. In lieu of giving the model more information while it is replying, you go back and update the model itself.
Then you train the model using a dataset that you give to fine-tune it. They might include instances of your desired answer structure, your company’s writing style, industry-specific language, or a set of work patterns the model should learn. When training is complete, the modifications are permanently baked into the model's weights. Now it will write in your tone, use your vocabulary, and follow your formatting guidelines organically without you having to tell it every time.
Here is the key distinction between technologies that most users overlook: fine-tuning teaches the model how to behave, not what to know. It is excellent at making a model sound like your brand or follow a specific structure. It is poor at keeping a model up to date with new information, because every time your knowledge changes, you need to retrain and redeploy.
This is the core of how many businesses approach Fine-tuning development services USA providers deliver, particularly for high-volume, consistent output scenarios.
Where Fine-Tuning Excels:
You need the model to produce a very specific output format, for example, structured JSON, standardized reports, or templated emails.
Your domain uses specialized language that a general model handles poorly, like medical billing codes, insurance claim formats, or legal citation styles.
You are running inference at high volume and need speed, since a fine-tuned model skips the retrieval step entirely.
Your training data is stable and will not need frequent updates.
Your knowledge changes frequently, and you cannot afford to retrain every few weeks.
You have a small dataset. Fine-tuning without sufficient quality examples produces models that are inconsistent and prone to errors.
You need to show users where an answer came from. Fine-tuned models give no source, which is a problem in regulated industries.
Also Read : How to Build AI Agents for Business Automation in 2026
RAG vs. Fine-Tuning: A Direct Comparison
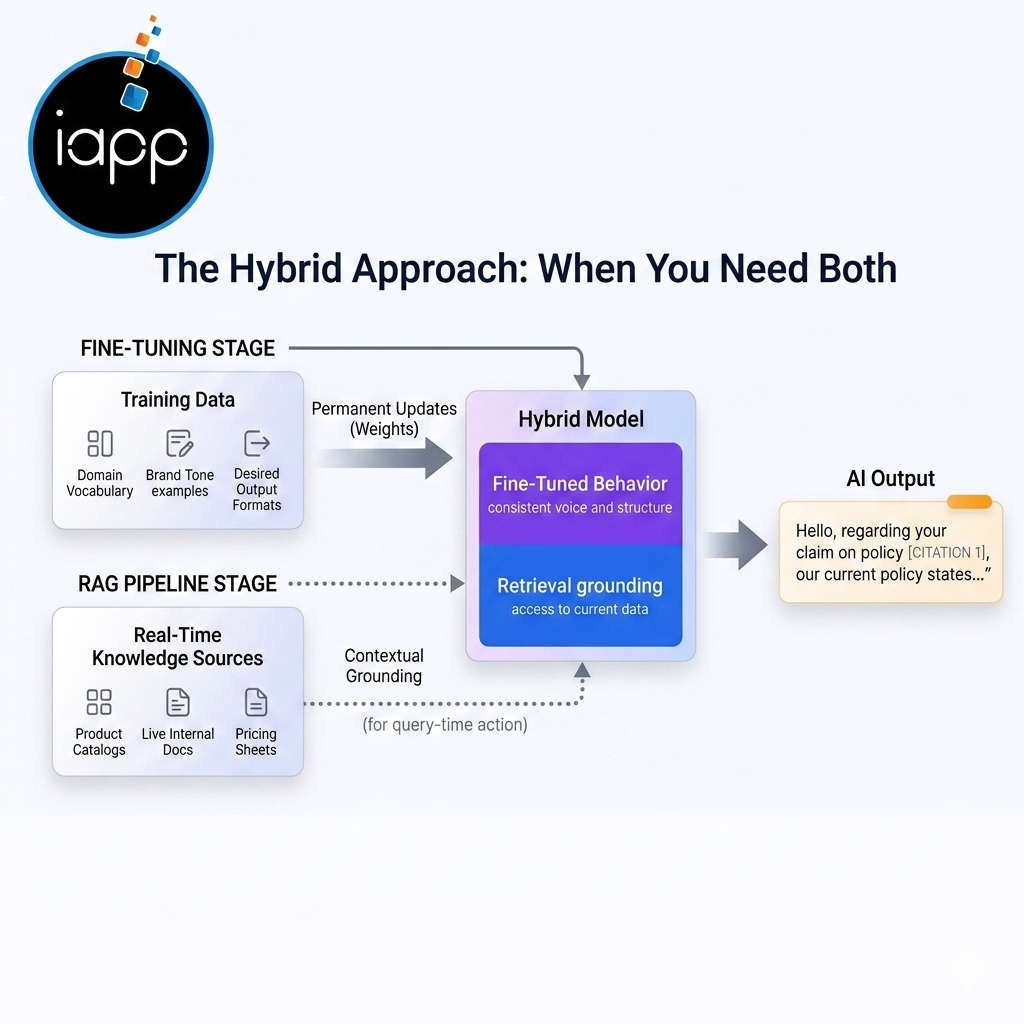
Here is something most comparison articles overlook. The most capable LLM applications in production today do not choose between RAG and fine-tuning. They use both.
The pattern works like this: you fine-tune the model to give it your preferred tone and response format, as well as domain vocabulary. Then you layer a RAG pipeline on top so it can access your current documents and data whenever a query is requested. The result is a model that sounds like your company's voice and knows nitty-gritty things that your company knows.
A practical example would be a customer support assistant for a US insurance company. You fine-tune the model on thousands of past support tickets so it learns how your agents write and how claims questions are handled. You then connect it to a RAG pipeline over your live policy documents and state regulation databases. The model responds in your voice and with current, accurate policy details.
Hybrid architectures that combine retrieval grounding with fine-tuned behavior are among the most effective ways to reduce that figure for production deployments.
This is exactly the kind of architecture that dependable enterprise AI development teams are building in 2026, and it is what iApp Technologies designs for clients who need reliability at scale.
Also Read : How to Build an AI Automation System That Replaces Manual Workflows
Skip the debate. Answer these four questions instead.
If yes, start with RAG. Fine-tuning a model on data that will be outdated in weeks is a waste of your budget.
If yes, RAG is not optional. Industries subject to compliance requirements, from healthcare to finance to legal services, need answers that link back to the source document.
In case yes, fine-tuning should be part of your architecture, either standalone or combined with RAG.
If you cannot wait for a 4- to 16-week retraining cycle every time your knowledge updates, a RAG can serve you much better.
Most US businesses exploring Custom LLM Development Services USA for the first time will find that RAG is the right starting point. It is faster to deploy, much less expensive to update, and easier to control. However, fine-tuning becomes a robust addition once the core application is working and you have a clear picture of where output consistency is falling short.
This is how businesses customize LLMs without beginning from scratch or spending a significant amount of money on infrastructure they do not actually yet need.
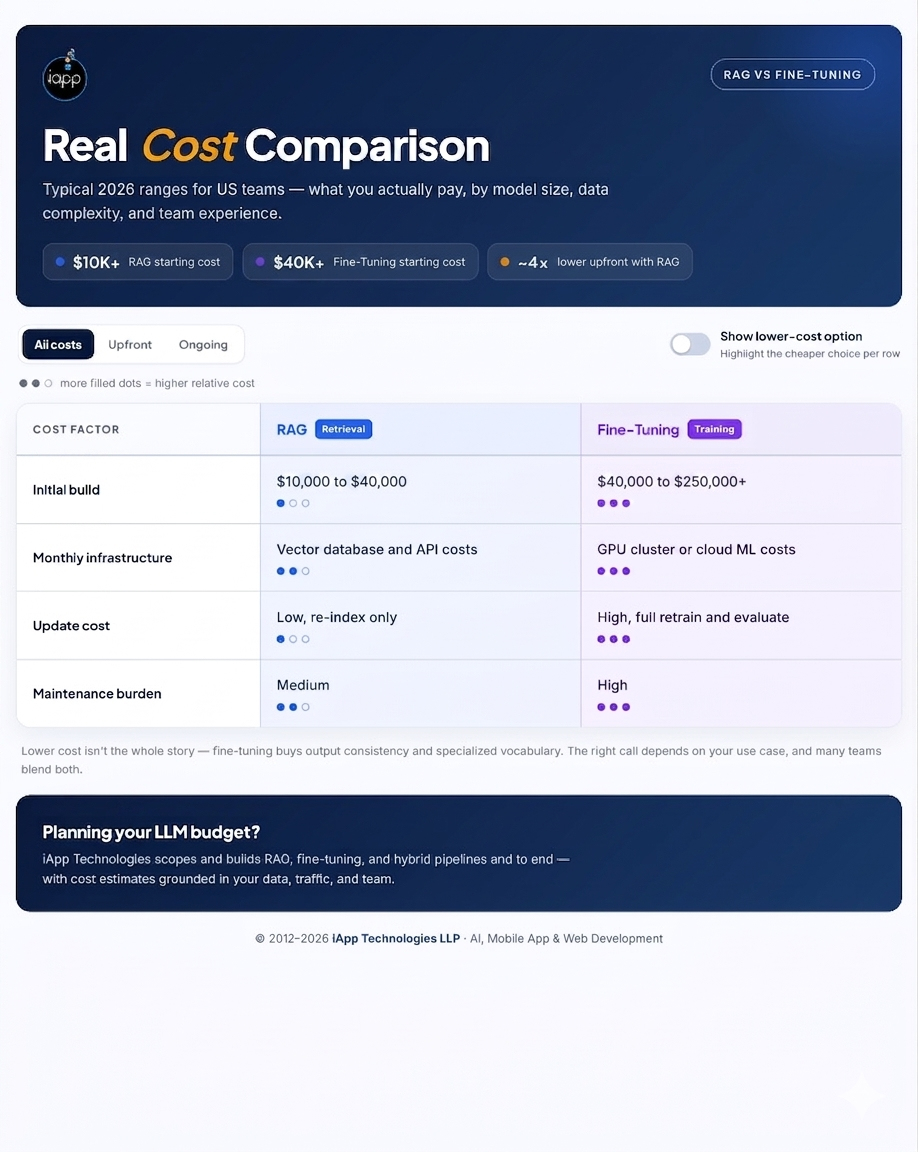
These figures reflect typical ranges for 2026 US market engagements, depending on model size, data complexity, as well as team experience.
At iApp Technologies, we have delivered 5,000+ digital products to clients across the US and globally. Our work in enterprise AI development spans RAG pipelines, fine-tuning workflows, and hybrid architectures for industries including healthcare, legal, finance, e-commerce, and SaaS.
We do not take a one-size-fits-all approach. Every engagement starts with a discovery phase where we map your data landscape, your update frequency, your compliance requirements, and your output goals. From there, we design the architecture that fits your situation, not the one that is easiest to build.
Whether you are looking for RAG development services USA to get something into production in a few weeks, fine-tuning development services USA to give your model a consistent brand voice, or a full hybrid system that does both, our team handles the full build from architecture design through deployment and monitoring.
RAG and fine-tuning are not rivals. They solve different problems, and the best production LLM applications in 2026 use a thoughtful combination of both.
If your data changes regularly, start with RAG. But, in case consistent behavior and domain-specific language are what you need, layer in fine-tuning. And if you want both at once, a hybrid architecture is the right pick.
The businesses that get this decision right will build AI applications that are much faster to deploy, affordable to keep, and far more trustworthy in production.
Ready to figure out which approach fits your specific situation? Get a free LLM architecture review from the iApp Technologies team. Our engineers will assess your data, your goals, and your budget and give you a clear recommendation before you commit to building anything.
Contact iApp Technologies today at iapptechnologies.com or call us at +1 833 342 9966.
RAG retrieves real-time information from your data sources at query time. Fine-tuning retrains the model on your data to shape its behavior permanently. RAG keeps knowledge current while fine-tuning builds deep domain expertise.
Yes, and it is often the smartest approach. Fine-tune for tone and domain behavior, then add RAG to keep responses grounded in live, accurate business data.
RAG suits businesses with frequently changing data. Fine-tuning works better for consistent style or specialized reasoning. Most enterprises benefit from combining both.
When your data changes often, when accuracy and source attribution matter, like in compliance, legal, or healthcare, or when you want to avoid the cost of repeated model retraining.
Simple AI integrations can begin around $15,000 to $30,000. Custom LLM apps with RAG or fine-tuning typically range from $50,000 to $200,000 or more depending on scope as well as complexity.
Look for proven LLM expertise and a strong delivery track record. iApp Technologies brings 5,000+ successful digital deliveries and hands-on experience building enterprise AI solutions across multiple industries.
Hands-on LLM experience, transparent processes, data security practices, and US compliance knowledge, as well as solid post-launch support. A good partner explains tradeoffs honestly before building anything.
Yes, iApp Technologies builds custom AI chatbots and conversational apps. We create a range of solutions, from customer support bots to internal knowledge assistants, all tailored to your distinct workflows and existing systems.
We at iApp Technologies offer custom LLM development, RAG pipelines, AI chatbots, generative AI integration, agentic AI, fine-tuning, and API development. Our team also offers ongoing model upkeep, along with strategic consulting to help you choose the right approach.
We begin with a discovery process to properly understand your data and compliance needs, as well as goals, before recommending a solution. From architecture to deployment, our team handles everything end to end with dedicated project management throughout.
 Jagwinder Singh
Jagwinder Singh


Before you leave, let our product consultant help you with a:
Have a project in mind or questions about our product?
Our team is here to help you with








 Discover content from creators around the world and for any interest.
Discover content from creators around the world and for any interest.